

L'IA et la Loi (Partie III) - La Partialités Algorithmique est Bonne Pour Vous
(Cet article est la troisième partie d'une série basée sur différentes conversations avec des avocats et des dirigeants sur l'Intelligence Artificielle, la nature de la technologie et son application aux problèmes de l'entreprise. La deuxième partie est ici. Avertissement: des références culturelles sont saupoudrées à gauche et à droite, vous avez été prévenu!)
Cet article traite des partialités dans l'intelligence artificielle, ce que c'est, ce que ce n'est pas et pourquoi c'est un avantage et non un problème.
La presse semble nous effrayée que l'IA prends notre travail, avec le cris que la Silicon Valley est éthiquement perdue, que des machines envahissent le monde ou font généralement des dégâts. Les préoccupations relatives à l’injustice algorithmique ne sont pas sans fondement, mais les mêmes recours que ceux que nous avons précédemment utilisés pour résoudre l’injustice s’appliquent.
Le parti pris expliqué
Une partialité est définie comme "un préjugé en faveur ou contre une chose, une personne ou un groupe par rapport à un autre, généralement considérée comme injuste", mais, dans l'IA et le contexte mathématique, le parti pris s'avère être quelque chose de souhaitable. 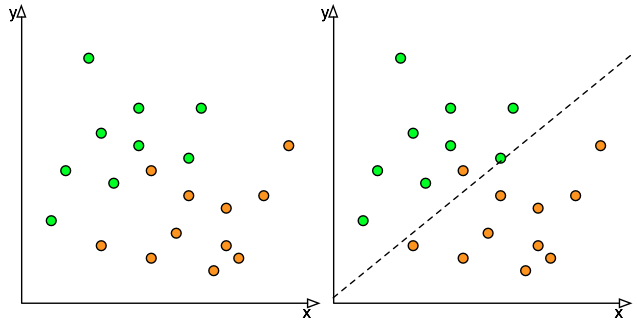 La Figure 1 est l’exemple de classification d'un blog précédent où nous avons un classificateur simple qui sépare les cercles oranges des cercles verts. Le classificateur n'est pas parfait: il fait un travail raisonnable dans la plupart des cas, mais il classe mal l'un des cercles oranges et il n'y a aucun moyen d'améliorer l'instance du classificateur à l'aide de cette technique de régression linéaire car aucune ligne droite ne séparera les cercles verts des cercles oranges.
La Figure 1 est l’exemple de classification d'un blog précédent où nous avons un classificateur simple qui sépare les cercles oranges des cercles verts. Le classificateur n'est pas parfait: il fait un travail raisonnable dans la plupart des cas, mais il classe mal l'un des cercles oranges et il n'y a aucun moyen d'améliorer l'instance du classificateur à l'aide de cette technique de régression linéaire car aucune ligne droite ne séparera les cercles verts des cercles oranges.
Cependant, supposons que les cercles oranges représentent un résultat vraiment négatif : un cancer non détecté ou une défaillance critique d'un avion, non signalé. La classification incorrecte est disproportionnée lorsque comparée avec une personne qui subie une biopsie inutile ou l'arrêt d’une machine pour maintenance préventive injustifiée. Étant donné que le coût de la classification erronée du cercle orange est si élevé, nous préférerions avoir des cercles verts classés de manière erronée plutôt que de manquer un des cercles oranges. Ce processus consistant à préférer délibérément une classe à une autre s'appelle une partialité (bias).
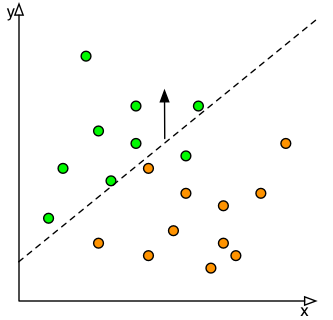 La figure deux est une représentation graphique de ce processus. Mathématiquement, si la régression linéaire est représentée par y = mx + b, nous augmentons la valeur de b de sorte que tous les cercles oranges soient inférieurs au seuil de classification. Dans la pratique, la classification n’est jamais parfaite et même l’application d’une partialité extrême peut entraîner une condition insatisfaisante. Cependant, ceci fournit un mécanisme d'atténuation des risques qui peut être quantifié en fonction des coûts / avantages attendus de chaque résultat et du classificateur disponible.
La figure deux est une représentation graphique de ce processus. Mathématiquement, si la régression linéaire est représentée par y = mx + b, nous augmentons la valeur de b de sorte que tous les cercles oranges soient inférieurs au seuil de classification. Dans la pratique, la classification n’est jamais parfaite et même l’application d’une partialité extrême peut entraîner une condition insatisfaisante. Cependant, ceci fournit un mécanisme d'atténuation des risques qui peut être quantifié en fonction des coûts / avantages attendus de chaque résultat et du classificateur disponible.
Supposons que vous utilisez le classificateur pour acheminer des formulaires vers deux bureaux de traitement, bureau vert et bureau orange. Le bureau orange a un seul employé chargé du traitement du formulaire. Le bureau vert comprend un comité de révision composé de cinq personnes qui doivent examiner le formulaire en profondeur. Supposons que le temps nécessaire pour renvoyer un formulaire mal acheminé à l'autre bureau est le même dans chaque cas. Le coût d'un formulaire mal acheminé vers le bureau vert est donc cinq fois plus élevé que celui du bureau orange puisqu'il prend simultanément le temps de cinq personnes. Pour atténuer le coût des formulaires mal acheminés, le classificateur privilégiera légèrement le bureau vert par rapport au bureau orange, calculé en fonction du nombre de formulaires verts et oranges au sein des données de formation et des coûts relatifs des formulaires mal acheminés. Cette classification optimisée nous permet d'atténuer les risques de la situation en utilisant l'IA et non en créant des risques inutiles avec L’IA.
Plus ça change, plus c'est la même chose
Alors pourquoi les gens sont-ils si préoccupés par la partialité? C'est la possibilité d'avoir son autonomie restreinte par une machine sans recours. PC LOAD LETTER du film Office Space nous en dit beaucoup. Pourtant, les risques de l'IA ne sont pas différents de ceux des autres technologies. La perception est que les algorithmes sont en quelque sorte faussés contre les principes éthiques et sont alimentés par des exemples de la presse tels que l’auto-étiquetage Google des Noirs en tant que gorilles ou le filtre de confidentialité de Google Street View ne parvenant pas à effacer le visage de quelqu'un. Mais en fin de compte, l'IA exécute ce que les humains lui ont programmé. Les IA ne sont pas autonomes, ils agissent en tant qu'agents d'une personne ou d'organisations. Les spéculations sur les problèmes de responsabilité liés aux décisions logicielles ont fait l'objet d'un article bien rédigé de John Kington[1] dans le contexte des lois courantes: il s'agit essentiellement de déterminer si le produit était défectueux ou s'il était utilisé correctement.
L’injustice et les préjugés à l’égard de certains groupes sociaux ne sont pas nouveaux et nous avons mis au point des règlements pour les traiter. Mais ce sont des droits humains qui ont besoin d'un être humain pour les concrétiser (Bien sur, l'IA fonctionne dans les deux sens: elle peut être formée pour rechercher l'injustice algorithmiquement en utilisant les mêmes données lisibles par machine). Redlining, le processus consistant à ignorer ou à promouvoir les services fournis à certaines communautés en fonction de leur emplacement physique est toujours un problème permanent et tant que la motivation économique sera présente, il sera nécessaire d'appliquer la réglementation. Le fait que le redlining soit le résultat d'une IA entraînée de manière non éthique ou d'une campagne postale non éthique est sans importance: c’est la volonté d’un humain et non d’une machine.
La possibilité qu’une IA au sein d’une organisation prenne conscience et réalise sa propre autonomie grâce à des manœuvres juridiques et financières est quelque chose qui restera vraisemblablement avec les personnages de Altered Carbon pour plusieurs années. Les efforts pour intégrer l’éthique dans les machines remontent à 1942 : vous souvenez-vous des lois de la robotique d’Isaac Asimov? Trois quarts de siècle plus tard, les robots sont toujours aussi idiots qu’un poteau de téléphone, effectuent des travaux répétitifs et chaque fois qu’un humain se blesse, c’est parce que quelqu'un a mal connecté le bouton d'arrêt d'urgence ou n'a pas verrouillé le contrôleur !
Comparez cela à un autre scénario de science-fiction: donnez à un système informatique des informations contradictoires et inconciliables, en négligeant le bouton d’arrêt d’urgence, ce qui entraînera l’assassinat de son équipage humain. L'humanité a déjà atteint cet objectif, cela s'appelle un accident du travail. Elles se produisent tous les jours et nous avons tout un écosystème d’organisations qui s’emploient à les prévenir: les principes de sécurité et d’éthique sont les mêmes, que la machine fonctionne à l’électricité, à l’hydraulique ou à la pneumatique.
Les problèmes hypothétiques ayant une forte implication morale font de bons livres, d’articles de magazine ou de discussions. Mais, ils ne correspondent pas bien à la planification opérationnelle ou aux situations réelles pour deux raisons: a) les urgences surviennent en raison d’un certain nombre de défaillances simultanées et b) de par leur nature, elles ne sont pas planifiées. Durant une urgence, par le temps que l’IA (et qui aurait besoin d'être très sophistiquée) a effectivement formulé le problème l'urgence va probablement été résolue d’une façon ou d’une autre.
L’IA devra-t-il vraiment être capable de choisir entre deux choix immoraux? Pas dans un avenir rapproché, principalement parce que l’IA n’est pas si intelligente et que nous disposons d’une puissance de calcul limitée. Les décisions éthiques nécessitent beaucoup d’informations contextuelles et même si vous savez quelle est la «bonne décision», sont exécution est difficile du point-de-vue algorithmique. La voiture autonome ne va pas choisir entre le bébé ou la grand-mère [2], elle va choisir le chemin avec la distance de freinage la plus longue, car il s'agit de la métrique la plus simple, la plus rapide et la plus fiable avec laquelle prendre une décision sage.
Enfin, chaque fois que les gens parlent de partialité algorithmique ou d'IA, ils parlent généralement d’une erreur. Exemple, en revenant à l’histoire de Google sur les gorilles : c’était une erreur. Classifiez des centaines de millions d’images chaque année et vous finirez par prendre une décision embarrassante. Idem pour les personnes: asseyez-vous sur une chaise et classer chaque jour les images de feux de circulations et de pierres tombales. Vous commettrez éventuellement une erreur, soit par inattention ou soit par ennui terminal.
Les raisons réelles d’une partialité non intentionnel d’IA sont les mauvaises données d’entraînement et / ou la réaffectation d’un moteur dont les objectifs de conception ne sont pas alignés sur l’objectif présent. Générer des données de formation coûte cher, prend du temps et nécessite un peu de va-et-vient pour que le système fonctionne correctement. Un moyen efficace de créer des données de formation n’est pas toujours disponible. Les étudiants gradués qui essaient de tester des algorithmes explorent leur département de recherche à la recherche de données de formation (anciens courriels, photos, extraits sonores) et finissent invariablement par prendre leurs amis et connaissances, ce qui crée un biais qui lui est propre. Suffisamment bon pour les tests académiques, ces modèles sont parfois utilisez par des entreprises en manque d’argent. De même, les codes disponibles pour chaque méthodologie d'intelligence artificielle sont limités. Quelle que soit l'optimisation construite et oubliée depuis longtemps, elle peut avoir des conséquences inattendues lorsqu'elle est utilisée pour une application différente.
Pourquoi avons-nous vraiment besoin d'IA?
C'est une bonne question. Pourquoi devrions-nous utiliser l'IA alors que nous pourrions utiliser des personnes pour faire le travail et créer des emplois? Indépendamment des forces du marché qui affectent les coûts de main-d'œuvre, le fait est que le taux de génération d'informations que nous générons est plusieurs fois supérieur à celui auquel nous sommes en mesure de les traiter. Ou, comme chaque parent vous le dira jamais, la capacité d'un enfant de 5 ans à poser des questions est extrêmement disproportionnée par rapport à la capacité combinée de ses parents à répondre à toutes.
Une partie du problème est l’être humain: nous n’avons pas beaucoup changé depuis la traversée du Rubicon par Julius Caesar, mais notre société a radicalement changé: peu nombreux ceux qui se souviendront d’un monde sans Internet où chercher le numéros de téléphone de quelqu'un en dehors de sa ville était une démarche sérieuse. Notre capacité à traiter personnellement les informations n'a pas suivi l'augmentation spectaculaire des données.
Utiliser plus de personnes pour traiter l'information n'est également pas une solution: à mesure que plus de personnes entrent dans le système, elles génèrent elles-mêmes plus d'informations et la situation devient un cercle vicieux. Selon un commentaire du PDG de Google, l'humanité crée plus de données, toutes les 48 heures, que toutes celles qu'elle avait fait avant 1993. Il n'y a pas de rattrapage avec les méthodes actuelles. Nos approches en matière de gestion des données ont abouti à des réponses embarrassantes[3] aux demandes d’AIPRP, estimées à plus de 80 ans. Il est évidemment inacceptable que des demandes d’informations simples ne puissent pas être traitées durant la vie d’un être humain.
La seule véritable solution viable est l'automatisation cognitive via l'IA. Il y a eu beaucoup de recherches sur la récupération d'informations et les réponses aux questions au fil des ans, la plupart remontant à une époque où la rareté des données facilitait la recherche. Des études sur la manière dont les êtres humains manipulent les informations ont révélé que nous ne sommes pas vraiment doués: selon le National Institute of Standards and Technology pour des tâches non triviales les personnes n’ont raison que 40% du temps[4][5]. À l'aide de comites de révision, de plusieurs accesseurs et de quelques méthodes statistiques, la courbe précision / rappel ne peut être portée qu’à 65% à 65%. Cela signifie qu’il faut réfléchir soigneusement à la précision lorsqu’on utilise soit l’intelligence artificielle et les personnes: les IA sont douées pour prendre des décisions simples, répétitives, tandis que les humains font mieux les décisions qui nécessitent beaucoup de contexte.
Un exemple que j’aime utiliser est la réunion d’affaires la plus importante de votre vie. Vous avez verrouillé la porte du bureau, débranché le téléphone, éteint le téléphone portable et fait jurer à tous qu’ils ne vous dérangeront pas. Lorsque votre conjoint a un accident de voiture, votre collègue frappera à la porte de votre bureau pour vous dire de prendre l'appel. L'IA fera ce que vous avez demandé et vous laissera tranquille. La valeur des personnes est qu’elles ont du jugement, pas les IA.
Conclusion
L'intelligence artificielle est là pour rester et au rythme où vont les choses, nécessaire au bon fonctionnement de notre civilisation. Comme pour tout nouvel outil, la lecture des avertissements de sécurité et du manuel est une bonne idée. Les écrivains, qu’ils soient universitaires, de presse ou de science-fiction, ont tendance à raconter la bonne histoire, à prédire des situations excitantes qui peuvent finir dans la morosité. Mais la réalité est que pour bien fonctionner, les projets d'intelligence artificielle doivent être centrés sur un problème unique et bien testés. L’idée de skynet, ou de War Games WOPR, qui prennent contrôle des ordinateurs NORAD est un bon scénario de film, mais cela ne se produira pas de sitôt.
References
- , “Artificial intelligence and legal liability”, in International Conference on Innovative Techniques and Applications of Artificial Intelligence, 2016.
- , “Should a self-driving car kill the baby or the grandma? Depends on where you’re from”, Technology Review, 2018.
- , “Your document request will be fulfilled by 2098”, The Toronto Star, Toronto, Ontario, 2018.
- , “What we have learned, and not learned”, The BCS/IRSG 22nd Annual Colloquium on Information Retrieval Research, pp. 2-20, 2000.
- , “Overview of the TREC 2011 legal track”, in Proc. 20th Text REtrieval Conference, 2010.