(Note: This is the second part of a series of posts that were based on several conversations with lawyers and executives about AI, the nature of technology and its application to business problems. The first part is here.)
At the heart of it, AI is about asking the following question: "Can I use the computer to make decisions that would normally require a human being?" Of course, the obvious answer is yes; human beings make all sorts of decisions all day long, ranging from the complex to the mundane. 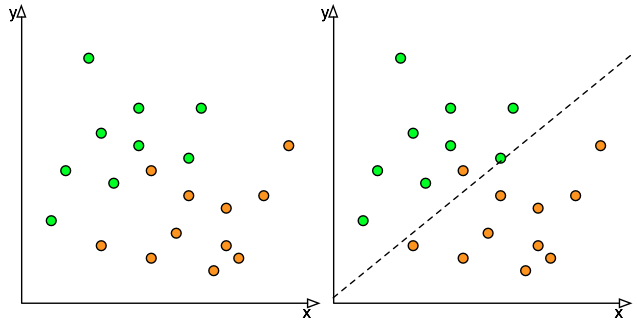 Accounting and operations systems have been making decisions for human beings for years, be it from calculating credit scores and interest rates to determining the best time to order feedstock.
Accounting and operations systems have been making decisions for human beings for years, be it from calculating credit scores and interest rates to determining the best time to order feedstock.
Let's use a simple example to explain the difference. Take the plot on the right hand side where I have orange dots and green dots. With basic statistical methods (linear regression was invented in the early 1900's[1]), we can create a simple classifier that will separate the green from the orange by simply drawing a line through the graph. It's not perfect, some oranges are misclassified as green and vice-versa, but we do very well with a really simple method.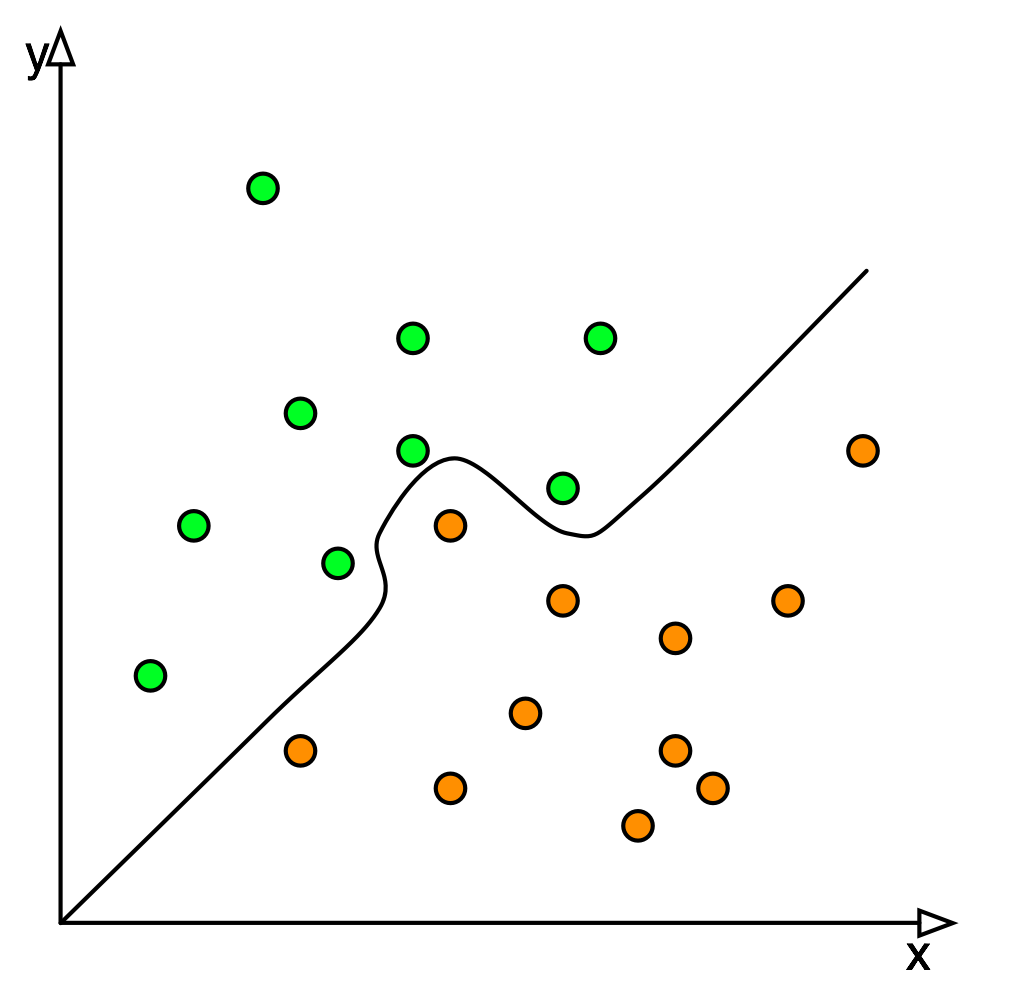 We can do better using mathematical techniques that are more sophisticated, see a non-linear method on the left, but fundamentally the problem remains simple: telling the granny smith apples from the oranges.
We can do better using mathematical techniques that are more sophisticated, see a non-linear method on the left, but fundamentally the problem remains simple: telling the granny smith apples from the oranges.
The problem is simple to solve because it is well defined. The objective is clear, the definition of success is clear (keep both sets of dots separated) and the way to tell them apart is by their colour. The only thing that remains is applying the recipe that matches the problem, a linear regression in this case, to solve the problem. Loosely speaking, there is no intelligence needed because the problem defines its own process to a solution.
Similarly, let's take another toy problem: tic-tac-toe. Every school child, even those that don't eventually end up working on AI, learns that the game can be tied or won by the first person playing. The second player can always force a tie, but can never win the game. All of us learn this by playing the game repeatedly while young: children over time explore the set of possible game layouts in tic tac toe and eventually learn that there are a finite number of starting X's and O's that can lead to victory or loss.
Very roughly, there are over 360,000 possible positions in tic-tac-toe. One basic machine learning method to learn to play tic-tac-toe is brute-force: try every single move and counter-move until every game is enumerated and then only choose moves that end in winning the game. Obviously, children can't keep track of 360,000 tic-tac-toe boards at the same time and while effective, the method does not scale well even for computers (Your desktop computer can't store the 10^47 possible combinations of chess). Therefore, children learn to take shortcuts and reduce those 360,000 positions into a set of starting moves that ensures that they win the game every time. That is intelligence: no one taught them the process required to find the solution, they just did. Artificial Intelligence is the science of creating algorithms that can do the same for certain classes of problems.
We say "classes of problems" because we only have the computing power and the programming know-how to handle limited problems, like recognizing a person, a text or a musical genre. This is different from what people sometimes refer to as "True AI", which is the human-like machine that walks and talks (and invariably tries to take over the world) on television shows. In my opinion, you are unlikely to have the Terminator do your filing for you anytime in the near future.
However for specific types of problems, AI works very well: classification, clustering, searching, reduction, etc... In turn, this means that the most of the work that goes into implementing an AI engine is actually trying to match very simple mathematical solutions to complex business problem. Going back to our first example of apples and oranges, the problem was delivered on a plate: colour and position. The solution needs more thinking when the problem isn't so well defined. In some cases, we know that some of the dots are different but not why or which ones (eg: Outlier Detection). In others, the objective may be to "Group the similar dots together" without having any idea of what makes the dots similar (eg: Market Segmentation).
Machine Learning vs Artificial Intelligence
In the vernacular, the terms Machine Learning and Artificial Intelligence are sometimes used interchangeably through they refer to different things. Artificial Intelligence is the catch all phrase for different computational techniques that have an intelligence component to them irrespective of the flexibility or adaptability of the method. Machine Learning refers to methods that are capable of learning themselves from the data without having their decision model encoded by a human being.
Take a program that can play tic-tac-toe. It clearly has an intelligence component in order to function, but the software will not learn from its interaction with the user (The problem is simple enough that there is no point to). But a program that recognizes cats in videos needs a machine-driven learning component is order for it to learn what a cat looks like.
Classifying And Finding Things With Artificial Intelligence
The figure below represents a very simplified block diagram of the AI process for classification; starting from the left to the right. We have a data set that we want processed, which can be documents, images, songs, video, etc... In practice, not everything within that data set is relevant to the context of what we are trying to do and so we transform each document into a set of features that we think are valuable to solve our problem. A feature might be a specific word in a document, another might be the word's part-of-speech (verb, noun, adverb, etc) or a typographical aspect such as the word being underlined.
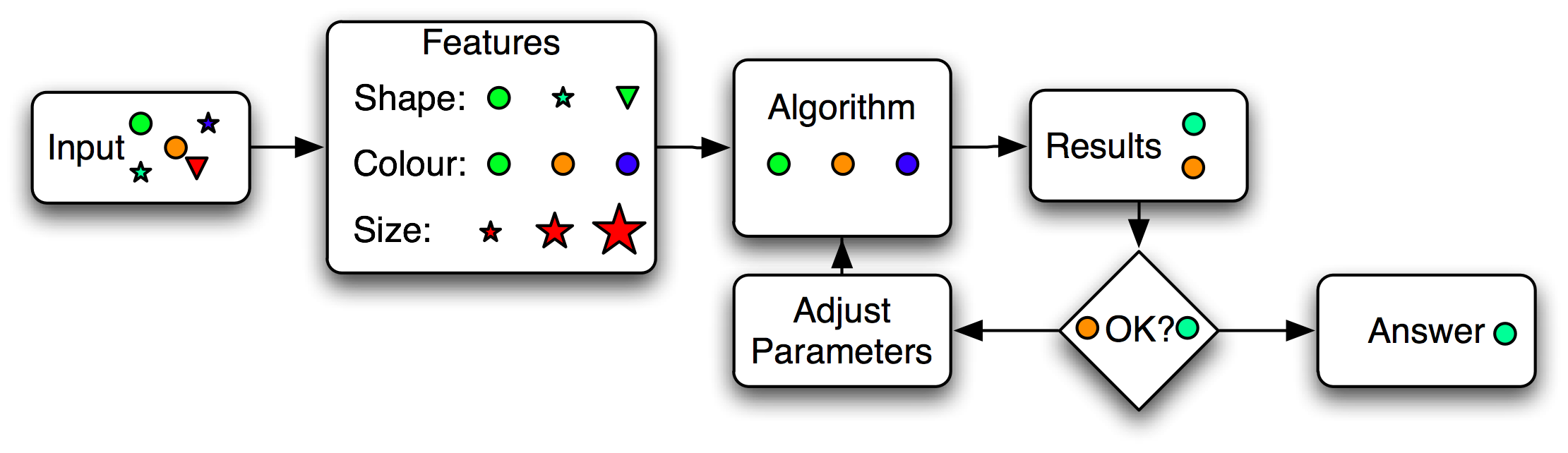
Since the feature set explicitly determines what part of the data set the algorithm will actually look at, feature generation is an extremely important part of the Artificial Intelligence process. It has spawned it's own field of study, Feature Engineering, and at times some have insisted that Artificial Intelligence is carefully crafted Feature Engineering. In practice, many engines have enough computational resources that they will simply generate every feature possible from the input data and the algorithm will simply choose the features that are most promising (This is called the "Throwing things at the wall to see what sticks" approach). It's wasteful, but computing time has become much cheaper than the people time required to create an efficient design.
The algorithm is the brain of AI, which is ironic in that the algorithm in itself is usually very simple and generic; the same algorithm that flies a flying drone might be the same that keeps your phone camera images from being blurry. However, the devil is in the details and the implementation of the algorithm is usually not portable from the phone to the drone. Examples of algorithms might be k-means, C4.5 or okapi, each one trying to perform the task of clustering, rule generation or information retrieval. As part of the process, the algorithm will take in the features and select the most promising. As part of that selection, some external information such as a trained model or parameter might be provided to the algorithm to guide it's decision making.
The results are then checked against a benchmark, sometimes called a gold standard, to ensure that the system is doing what it is supposed to. If the results aren't exactly what is required the model or the parameters of the algorithm might be changed.
Overall, the basics of AI aren't that complex, but its implementation and arrangement needs to be focused on the objectives of the project, otherwise one gets into the loop of "garbage in, garbage out". Depending on the case, the tuning of parameters can be frustrating and model generation becomes an art and not a science. There are many different frameworks, libraries and code bases available both freely and commercially to experiment with which I encourage you to do.
Next: Part III - Algorithmic Bias is good for you.



 Most Secret War
Most Secret War
 Artificial Intelligence and the Law
Artificial Intelligence and the Law Processing legal documents with AI: Notes from the field.
Processing legal documents with AI: Notes from the field.